前章ではeBPFについて学びました。本章では、ユーザーから渡されたBPFプログラムを安全かつ高速に動かすための、検証器とJITについて説明します。
検証器
まずは、eBPFの検証器について学びましょう。検証器のソースコードはLinuxカーネルのkernel/bpf/verifier.cに書かれています。。
検証器は命令を1つずつチェックし、すべての分岐先をexit命令までトレースします。検証は大きく二段階(First Pass, Second Pass)に分けられます。
一段階目のチェックでは、深さ優先探索によってプログラムが有向非巡回グラフ(DAG; Directed Acyclic Graph)であることを保証します。DAGとはループを持たない有向グラフのことです。
このチェックにより、次のようなプログラムは拒否されます。
BPF_MAXINSNSを超える命令が存在する場合[1]- ループフローが存在する場合
- 到達不可能な命令が存在する場合
- 範囲外、あるいは不正なジャンプが存在する場合
二段階目のチェックでは、あらためてすべてのパスを探索します。このとき、レジスタの値に対して型や範囲を追跡します。
このチェックにより、例えば次のようなプログラムは拒否されます。
- 未初期化レジスタの利用
- カーネル空間のポインタのreturn
- カーネル空間のポインタをBPFマップへ書込
- 不正なポインタの読み書き
一段階目のチェック
DAGのチェックはcheck_cfg関数に実装されています。アルゴリズム自体は、再帰呼出を使わない深さ優先探索です。
check_cfgはプログラムの先頭から深さ優先探索の要領で命令を見ていきます。現在見ている命令に対してvisit_insnが呼ばれ、この関数で分岐先がスタックにpushされます。探索用スタックへのpushはpush_insnで定義されており、この中に範囲外へのジャンプと閉路検出が含まれています。
1 | if (w < 0 || w >= env->prog->len) { |
なお、visit_insnは1回につき、必ず1つのパスしかpushしません。(あるいはDONE_EXPLORINGでその命令の分岐先がすべて探索終了したことを知らせます。)例えばBPF_JEQのように条件分岐がある場合、visit_insnは最初の分岐先のみをpushします。深さ優先探索なので、その分岐先の探索がすべて終了すると、またBPF_JEQに戻ってきます。するとBPF_JEQに対して再度visit_insnが呼ばれ、今度はもう一方の分岐先がpushされます。さらにそちらの探索が終了すると、BPF_JEQに対して3回目のvisit_insnが呼ばれ、そこでDONE_EXPLORINGが返され、BPF_JEQがスタックからpopされます。

条件分岐で一度に両方のパスをpushしなかったり、命令を取り出すときにpopしなかったり、一見非効率的に見えるけど、異常を検知したときに綺麗なスタックトレースを出力するための工夫なんだね。
例えば、次のようなプログラムはすべて一段階目のチェック機構により拒否されます。
1 | // 到達不能な命令がある |
1 | // 範囲外へのジャンプがある |
1 | // ループがある |
たとえ負の方向へのジャンプがあっても、ループしていなければ問題ありません。
1 | struct bpf_insn insns[] = { |
二段階目のチェック
eBPFにおける検証器のバグでもっとも重要になるのは、二段階目のチェックです。
二段階目のチェックは主にdo_check関数で定義されており、レジスタの型、値の範囲、具体的な値やオフセットを追跡します。
型の追跡
検証器はレジスタの値がどのような種類の値かをbpf_reg_state構造体で保持しています。例えば次のような命令を考えましょう。
1 | BPF_MOV64_REG(BPF_REG_0, BPF_REG_10) |
最初の命令ではスタックポインタをR0に代入しています。このとき、R0はPTR_TO_STACKという型になります。次の命令ではR0から8だけ引かれますが、まだスタックの範囲内を指しているため、PTR_TO_STACKのままです。他にも、ポインタとポインタの足し算は定数扱いになるなど、命令の種類とレジスタの型、値の範囲などに応じて、新しい型は変わります。
型の追跡は、不正なプログラムを調べる上で必須です。例えばスカラー値をポインタとしてメモリからデータをロード・ストアできてしまうと、任意アドレス読み書きになってしまいます。また、コンテキストを受け取るヘルパー関数にBPFマップなど自由に操作できるポインタを指定できてしまうと、偽のコンテキストを使わせることができます。
レジスタの型(enum bpf_reg_type)としては、例えば以下のような型が定義されています。
| 型 | 意味 |
|---|---|
NOT_INIT |
未初期化 |
SCALAR_VALUE |
定数など一般的な値 |
PTR_TO_CTX |
コンテキスト(BPFプログラムの呼出引数)へのポインタ |
CONST_PTR_TO_MAP |
BPFマップへのポインタ |
PTR_TO_MAP_VALUE |
BPFマップの値へのポインタ |
PTR_TO_MAP_KEY |
BPFマップのキーへのポインタ |
PTR_TO_STACK |
BPFスタックへのポインタ |
PTR_TO_MEM |
有効なメモリ領域へのポインタ |
PTR_TO_FUNC |
BPF関数へのポインタ |
レジスタの初期状態はinit_reg_state関数で定義されます。
定数の追跡
検証器ではレジスタの定数を追跡しています。値は区間を使った抽象化で追跡されます。つまり、各レジスタについて、その時点でレジスタが取り得る「最小値」と「最大値」を記録しています。
例えば、R0 += R1 (BPF_ADD)の時点でR0とR1がそれぞれ[10, 20],[-2, 2]を取り得る場合、演算(抽象解釈)後のR0の値は[8, 22]になります。
演算に関するこの挙動はadjust_reg_min_max_vals関数とadjust_scalar_min_max_vals関数で定義されています。

具体的な値が分からない解析過程では、値を抽象的な範囲で推測することが多いね。 健全(sound)な手法で抽象化しないと、解釈結果が間違うことがあるよ。
値の範囲追跡のため、検証器は各レジスタについて次のような値を保持・追跡しています。
| 変数 | 意味 |
|---|---|
umin_value, umax_value |
64-bitの符号なし整数として解釈したときの最小・最大値 |
smin_value, smax_value |
64-bitの符号付き整数として解釈したときの最小・最大値 |
u32_min_value, u32_max_value |
32-bitの符号なし整数として解釈したときの最小・最大値 |
s32_min_value, s32_max_value |
32-bitの符号付き整数として解釈したときの最小・最大値 |
var_off |
レジスタ中の各ビットの情報(具体的な値が判明しているビット) |
var_offはtnumと呼ばれる構造体で、maskとvalueを持ちます。maskは値が不明なビットの場所が1になっています。valueは判明している場所の値です。
例えば、BPFマップから取得した64ビットの値は、最初すべてのビットが不明なので、var_offは
1 | (mask=0xffffffffffffffff; value=0x0) |
になります。このレジスタに対して0xffff0000をANDすると、0とANDした箇所は0になることが分かるので、
1 | (mask=0xffff0000; value=0x0) |
になります。更に0x12345を足すと、下位16ビットは分かるので
1 | (mask=0x1ffff0000; value=0x2345) |
となります。繰り上がりの可能性を考慮してmaskのビットが1つ増えていることに注意してください。この時点でのumin_value, umax_value, u32_min_value, u32_max_valueはそれぞれ、0x1ffff0000, 0x1ffff2345, 0xffff0000, 0xffff2345です。
では、具体的な実装を見てみましょう。BPF_ADDの場合、次のようにレジスタが更新されます。
1 | case BPF_ADD: |
scalar_min_max_addでは、次のように整数オーバーフローなども考慮した範囲計算が実装されています。
1 | static void scalar_min_max_add(struct bpf_reg_state *dst_reg, |
乗除や論理・算術シフトなど、すべての演算に対してこのような更新処理が実装されています。計算した値の範囲は、スタックやコンテキストなどのメモリアクセスにおいて、オフセットが範囲内に収まっているかを確認するのに使われます。
例えば、スタックの範囲チェックはcheck_stack_access_within_boundsで定義されています。即値の場合など、値が定数と分かっている場合は通常のオフセットチェックをします。
1 | if (tnum_is_const(reg->var_off)) { |
一方で具体的な値がわからない場合は、オフセットが取り得る最小・最大値を確認します。
1 | } else { |
そして、それらの値を使って範囲チェックをしています。
1 | err = check_stack_slot_within_bounds(min_off, state, type); |
このように、レジスタや変数の値の範囲を追跡する手法は、BPF以外でも、最適化・高速化が要求されるJITで頻繁に使われます。

実行速度向上のために、できるだけ事前にセキュリティチェックを終わらせているんだね。
次のようなプログラムはすべて二段階目のチェック機構により拒否されます。
1 | // 未初期化のレジスタの利用 |
1 | // カーネル空間のポインタのリーク |
抽象化された値が定数にならない例を考えてみましょう。
1 | int mapfd = map_create(0x10, 1); |
まず、値のサイズが0x10のBPFマップを用意しています。BPFプログラムの最初のブロックでは、BPFマップの先頭の値と、そのポインタをそれぞれR6, R7に代入します。(map_lookup_elemの戻り値R0は、第二引数のインデックスで指定した要素へのポインタです。NULLを返す可能性があるため、条件分岐でNULLを除去しています。)
最後のブロックでポインタR7にR6の値を加算しています。R6はBPFマップから取ってきた値なので任意の値を取れます。しかし、BPF_ANDで0b0111とandを取っているため、この時点でR6の取り得る値は[0, 7]になります。今回BPFマップ値のサイズは0x10にしてあるため、値のポインタの先頭から7足して、そこからBPF_LDX_MEM(BPF_DW)で8バイト取得しても問題ありません。そのため、このBPFプログラムは検証器を通過できます。
しかし、BPF_ANDの値を0b1111などにすると、検証器がプログラムを拒否することが分かります。
1 | ... |
値のサイズが16なのに、最大オフセットは15で、そこから8バイト取得しようとしているため、範囲外参照が起きるためです。
また、一部の命令は値の追跡をサポートしていません。例えばBPF_NEGを通ると必ずunboundになるため、次のプログラムは(実際には問題ないですが)検証器に拒否されます。
1 | BPF_ALU64_IMM(BPF_AND, BPF_REG_6, 0b0111), // R6 &= 0b0111 |
このように、二段階目のチェックではレジスタを追って、メモリアクセスやレジスタ利用時に未定義動作が起きないことを保証しています。逆に言えば、このチェックが間違っていると、メモリアクセスで範囲外参照を起こせてしまうわけです。具体的な手法は次の章で説明します。
ALU sanitation
ここまで説明した型チェック・範囲追跡が検証器の仕事なのですが、eBPFを悪用する攻撃が増えたため、近年では新たにALU sanitationという緩和機構が導入されています。
検証器のミスにより攻撃が発生する原因は、範囲外参照を起こせるためです。例えば下図のように、検証器が0と推測しているのに実際の値が32の「壊れた」レジスタができたとします。攻撃者は図のように、サイズ8の値を4つ持つマップのポインタに壊れた値を足します。検証器は値を0だと思っているので、加算後もマップの先頭を指したままだと思っていますが、実際には範囲外を指しています。この状態でR1から値をロードすると、検証器に検知されることなく範囲外参照ができます。
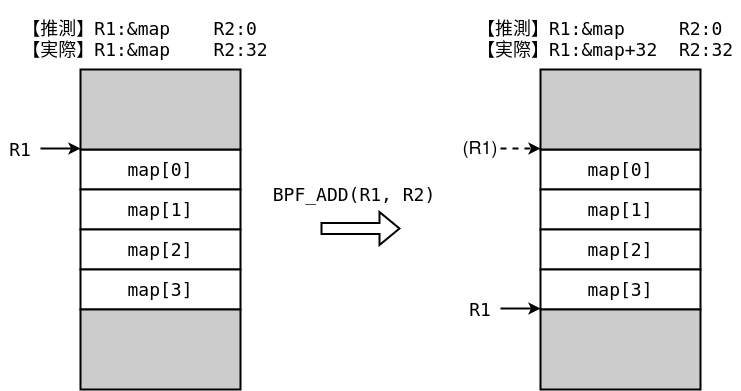
このような検証器の誤りによる範囲外参照を解決するため、ALU sanitationという緩和機構が2019年に導入されました。[2]
eBPFでは、ポインタに対してはスカラー値の足し引きだけが演算として許可されています。ALU sanitationでは、ポインタとスカラー値の足し引きにおいて、スカラー値側が定数であると分かっているとき、それを定数演算BPF_ALUxx_IMMに書き換えます。例えば、R1がマップのポインタで、R2が推測値0、実際値1のスカラー値を持つレジスタだとします。このとき
1 | BPF_ALU64_REG(BPF_ADD, BPF_REG_1, BPF_REG_2) |
は、検証器がR2を定数0だと思っているため、
1 | BPF_ALU64_IMM(BPF_ADD, BPF_REG_1, 0) |
に変更されます。このパッチはもともとSpectreというサイドチャネル攻撃を防ぐために導入されたものですが、検証器のバグを悪用する攻撃にも効果があります。
さらに、スカラー側が定数でない場合は、alu_limitという値を用いて命令がパッチされます。
alu_limitは「そのポインタから最大でどれだけの値を足し引きできるか」を示す数値です。例えばサイズ0x10のマップ要素の先頭から2バイト目を指していて、BPF_ADDによるスカラー値との加算が発生する場合、alu_limitは0xeになります。先ほどと同じように
1 | BPF_ALU64_REG(BPF_ADD, BPF_REG_1, BPF_REG2) |
という命令を考えます。ALU sanitationでは、この命令が次のようにパッチされます。(BPF_REG_AXは補助レジスタです。)
1 | BPF_MOV32_IMM(BPF_REG_AX, aux->alu_limit), |
先ほどと同じく、サイズ0x10のマップ要素の先頭から2バイト目を指しているレジスタR1に対するスカラー値R2の加算を考えます。スカラー値R2がalu_limitである0xeを超えているにも関わらず、何かしらのバグで検証器が検知できていないとします。例えば、次のような命令列が生成されます。
1 | BPF_MOV32_IMM(BPF_REG_AX, 0xe), |
まず、最初の2命令で0xe-R2を計算します。R2が範囲内の場合は正の値あるいはゼロになりますが、範囲外の場合は負の値になります。次のOR命令では、AXとR2が異なる符号を持つ場合に、最上位ビットが1になります。つまり、範囲外参照が起きる時は、この時点で最上位ビットが1になっているはずです。
その後NEGで符号を反転させ、算術シフトで64ビットシフトます。範囲外参照が起きる場合はAXに0が、そうでなければAXに0xffffffffffffffffが入ります。最後にR2とAXのANDを取り、これが最終的に使われるオフセットとなります。
この操作により、万が一範囲外参照が発生する状況になったら、ポインタに0が加算されるようになります。
各操作の可否
第二段階のチェックにより禁止されている処理を大まかに整理すると、次のようになります。
- レジスタ
- R10(FP)への書き込み
- 未初期化レジスタの読み込み
- コンテキスト
- コンテキストの範囲外の読み書き
check_ctx_accesses中のコンテキストに対応するコードが許可しない読み書き
- BPFマップ
- データの範囲外の読み書き
- ポインタの書き込み
- スタック
- スタックの範囲外の読み書き
- 未初期化領域の読み込み
- 8バイト(32-bitなら4バイト)でアラインされていない(可能性がある)読み書き
- ポインタの下位32ビット(
BPF_W)など部分的な読み書き
- メモリ全般
- NULLポインタ持つ可能性があるポインタの読み書き
- 関数
- 定義と異なる型・値の引数渡し
マップに値を書き込むと、書き込み先の追跡範囲は消滅します。一方で、スタックにはポインタが書き込める上、書き込んだ値の範囲や型を記憶してくれます。その代償として、スタックには512バイトのサイズ制限があり、アラインされていないオフセットへの書き込みや、ユーザー空間からの読み書きはできません。
JIT (Just-In-Time compiler)
検証器を通過したBPFプログラムは、どのような入力で実行しても安全であることが(検証器が正しいという仮定の下で)保証されています。したがって、JITコンパイラは与えられた命令をCPUに合った機械語に直接変換することになります。
CPUごとに機械語は異なるため、JITのコードはarchディレクトリ以下に書かれています。x86-64の場合、arch/x86/net/bpf_jit_comp.c中のdo_jit関数に記述されています。
例えば、乗算(BPF_MUL)を機械語に変換するコードは以下のようになっています。
1 | case BPF_ALU | BPF_MUL | BPF_X: |
0x0F, 0xAFがimul命令に対応する命令コードになります。
検証器が正しくても、JITで生成されるコードが検証器と違う挙動をしたら、それもexploitableになりそうだね。
ここまででexploitに必要なeBPF内部の仕組みを概ね説明しました。次章では、実際に検証器のバグを利用して権限昇格していきます。
(1) ポインタどうしの比較
(2) ポインタとポインタの減算
(3) スタックへのポインタ値の書き込み
(4) BPFマップへのポインタ値の書き込み
(5) 範囲内だがアラインされていないスタックアドレスの読み書き