前章ではHolsteinモジュールのUse-after-Freeを悪用して権限昇格をしました。3度目の正直、Holsteinモジュールの開発者は3つ目のパッチでモジュールを修正し、Holstein v4を公開しました。開発者曰くもうこれ以上脆弱性はなく、今後はアップデートも停止するそうです。本章では、最終版のHolsteinモジュールv4をexploitしていきます。
パッチの解析
最終版v4はここからダウンロードできます。まずはv3との差分を見ていきましょう。
まず起動スクリプトrun.shですが、マルチコアで動作するように変更されています。
1 | - -smp 1 \ |
プログラムの方は、メモリリークとUse-after-Freeが修正されています。
1つ目がopenで、既に誰かがドライバを開いている際には変数mutexが1になり、openが失敗するように設計されています。
1 | int mutex = 0; |
つまり、open中に再度ドライバを開くことはできなくなりました。開いているファイルディスクリプタをcloseするとmutexが0に戻り、再度open可能になります。
1 | static int module_close(struct inode *inode, struct file *file) |
脆弱性はどこにあるでしょうか?少し考えてみてください。
Race Condition
今回のドライバの実装は完璧のように思えるかもしれませんが、実はまだ複数のプロセスかリソースにアクセスするという状況を完全に考慮できていません。
OSは複数のプロセス(スレッド)を同時に実行できるようにコンテキストスイッチを実装し、マルチスレッドで複数のプログラムを動かせるようにプロセスを管理しています。コンテキストスイッチが発生するタイミングは関数のような大きい粒度ではなく、アセンブリの命令単位での切り替え[1]になります。当然、module_open関数の実行中にコンテキストが切り替わる可能性もあるわけです。
この章では、このようなマルチスレッド・マルチプロセスで発生する競合問題(Race Condition)を悪用して、exploitを書いていきます。
発生条件
まずは競合状態がどのような結果を生むかを考えます。例えば次のような実行順序でコンテキストが切り替わった場合を考えます。
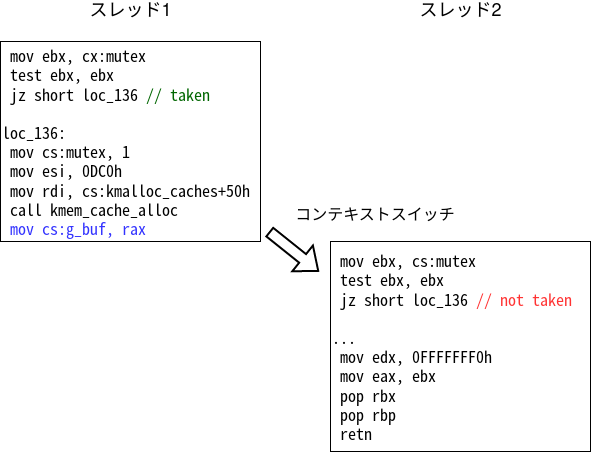
初めにmutexには0が入っているのでスレッド1の条件分岐でジャンプが発生し、g_bufを確保するパスに到達します。さらに青色の命令でg_bufにアドレスが入ります。
次にコンテキストスイッチが発生して実行がスレッド2に切り替わります。スレッド2の段階ではmutexに1が入っているため、条件分岐ではジャンプが発生せず、EBUSYを返すパスに到達してopenが失敗します。
したがって、この例ではmodule_openが開発者の期待した通りに動いています。
次に下の図の実行順序を考えます。
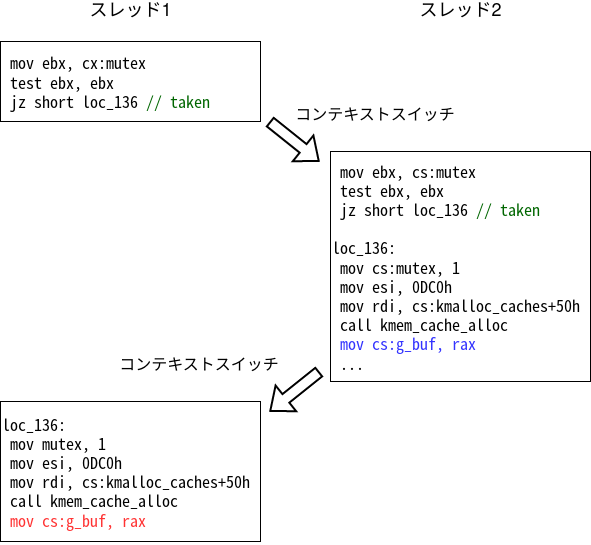
先程と同様にスレッド1ではg_bufを確保するパスに到達します。しかし、今回はmutexに1を入れる前にコンテキストスイッチが発生します。
するとスレッド2の条件分岐の段階ではまだmutexに0が入っているため、g_bufを確保するパスに到達します。そして青色の命令でg_bufに確保されたアドレスが入ります。
当然その後コンテキストスイッチが発生してスレッド1に実行が切り替わるのですが、スレッド1はバッファを確保して赤色の命令でアドレスをg_bufに保存します。
すると、どちらのスレッドでもopenが成功してしまい、スレッド1が確保したアドレスが両方のスレッドから使える状態になることが分かります。
このように、カーネル空間のコードを設計する際は、常にマルチスレッドを考慮した設計にしないとバグが起きてしまいます。

変数mutexの読み書きにatomicな演算を使わなかったことが原因で起きた競合だね。
openが2回成功すると、片方に対してcloseが呼ばれてもg_bufは解放されたポインタを指したままなので、前章と同様のUse-after-Freeが引き起こせます。
競合を成功させる
まずはopenの競合が本当に可能かをコードを書いて調べましょう。
複数のスレッドでopenを立て続けに呼べば簡単に競合は起きますが、競合が成功したことを判定しなければループを抜け出せません。競合の判定方法は様々ですが、基本的には2つのスレッドからreadして、両方成功すれば競合に成功したと判断する方法が妥当でしょう。また、今回は無駄なread呼び出しを減らすため、ファイルディスクリプタを確認することにしました。というのも、2つのスレッドからopenに成功した場合、かならずどちらかのファイルディスクリタは4になるはずです。
著者は以下のように、同じ関数を2スレッドで動かすことで競合状態を作れるRaceを書きました。もちろんメインスレッドでループしても構いませんし、競合状態の判定方法はみなさんの好きなように設計してください。なお、コンパイルオプションに-lpthreadを付けてlibpthreadをリンクすることを忘れないように注意しましょう。
1 | void* race(void *arg) { |
これでほぼ100%の確率でRaceに成功することが分かります。Race成功までにかかる時間もミリ秒単位で、primitiveとして十分に使えるものになりました。
データ競合とは、メモリ中のある場所のデータを2つのスレッドが同時に(非同期に)アクセスする(少なくとも片方は書き込み)状態を指します。そのため、データ競合は未定義動作を引き起こします。データ競合は適切な排他制御やアトミック演算により解決できます。
一方で競合状態は、マルチスレッドの実行順序によって異なる結果が生まれる状態を指します。競合状態はロジックバグなどと同じで「プログラマがそう書いたからそう動いている」だけであり、予期しない動作(unexpected behavior)は起きますが未定義動作(unsound behavior)が起きることとは関係ありません。マルチスレッドによりプログラマの意図に反する結果が生まれれば、そのときは競合状態のバグがあると言えます。
今回のドライバには実装ミスによる競合状態があり、バッファのポインタにおけるデータ競合が発生します。
CPUとHeap Spray
今回のようにマルチスレッドで競合のexploitを実装することは多々ありますが、この際に注意が必要なことがあります。
複数スレッドで競合状態を引き起こしているということは、攻撃時に複数のCPUコアが使われています。すると、当然どちらかのCPUコアからmodule_openが呼ばれてkzallocでメモリ領域が確保されます。
ここで、以前Heap Overflowの章で説明したSLUBアロケータの特徴を思い出してみましょう。SLUBアロケータではオブジェクト確保に使うslabをCPUごとのメモリ領域に管理しています。
つまり、今main関数が動いているスレッドと異なるCPUコアから確保されたg_bufがkfreeされると、当然確保時のCPUコアに対応するslabにリンクされます。すると、その後でmainスレッドからHeap Sprayをしても、kfreeされたg_bufと被ることはありません。
したがって、今回のような状況では複数スレッドでHeap Sprayを走らせるように注意しましょう。
また、/dev/ptmxを開くことで新たにファイルディスクリプタが作られますが、1つのプロセスが作れるファイルディスクリプタの数には限りがるので、大量のsprayが要るときは、sprayがヒットした時点で関係の無いファイルディスクリプタを閉じるといった工夫も必要です。
1 | void* spray_thread(void *args) { |

sched_setaffinity関数を使うと、スレッドが利用するCPUを制限できるから、コア数が増えても2コアの時と同じような挙動になるよ。
権限昇格
あとはこれまで同様の手順で権限昇格するだけです。
データ競合によりUse-after-Freeを引き起こし、そこにHeap Sprayでtty_structを載せるという一連の流れを関数にすると、複数回Use-after-Freeを起こすのが簡単に書けます。
サンプルのexploitはここからダウンロードできます。
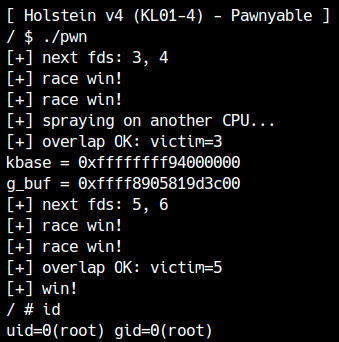
競合状態のexploitはデバッグが難しいため、最初の段階で理論を実現できるかと、高い確率で安定してraceを引き起こすようなprimitiveが作れるかがexploit開発の肝となります。
CPUによっては最適化のために命令の実行順序が変わるといったさらに粒度の低い話もありますが、今回は関係ないので説明しません。 ↩︎